A suite of codes for performing lattice gauge theory by theoretical physicists consumes a large fraction of supercomputer cycles worldwide. The core communication paradigm seems to be an adjacent-neighbor exchange on a four-dimensional grid. The ratio of message passing work to computational work is such that the effect of the network on application performance is non-negligible.
The code and more information is available from Fermilab. Here are my notes on configuration and compilation for a linux/ia64 cluster with the Intel ecc compiler. Many thanks to Don Holmgren of Fermilab for helping me learn how to run the code.
First, get the _collab version of the source, it has the useful benchmark in it. Unpack all the tars, don't worry that _basic will overwrite the initial Make_* files, they're identical. edit Make_linux_mpi: (extensive) edit generic/io_ansi.c: fseeko -> fseek edit include/config.h: define NATIVEDOUBLE, HAVE_64_BYTE_CACHELINE, undef HAVE_FSEEKO Put in links to the useful makefile for things to be built: ln -s ../Make_linux_mpi libraries/ ln -s ../Make_linux_mpi ks_imp_dyn2/ Ensure no parallel make, as the manual timestamps gets confused: unset MAKEFLAGS Build just the code of interest: cd ks_imp_dyn2 MAKEFLAGS= make -f Make_linux_mpi su3_rmd_symzk1_asqtad To make tags: ctags $(find ks_imp_dyn2 generic_ks generic \ libraries include -name '*.[ch]')
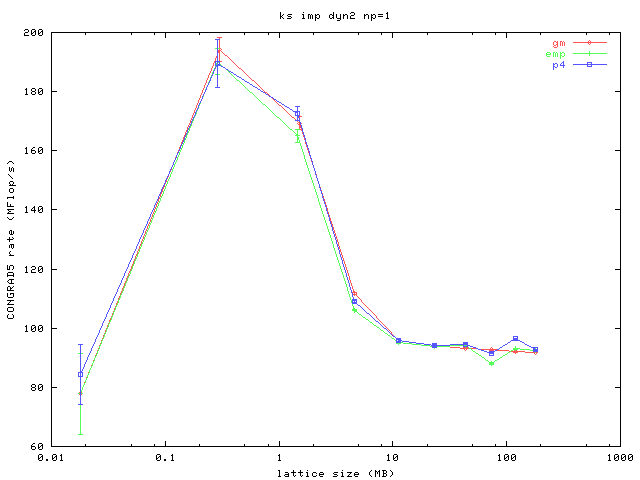
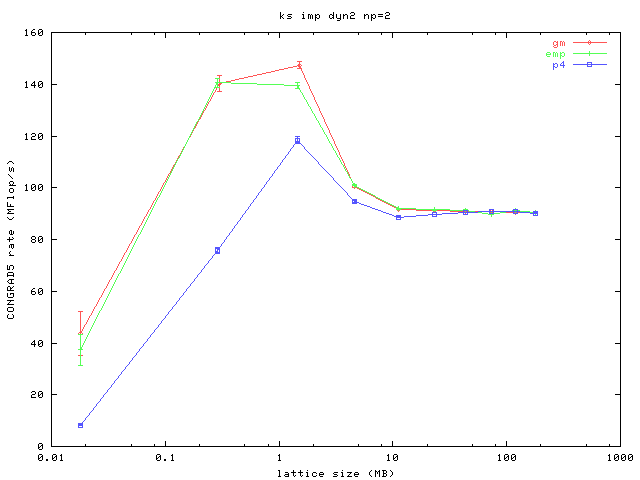
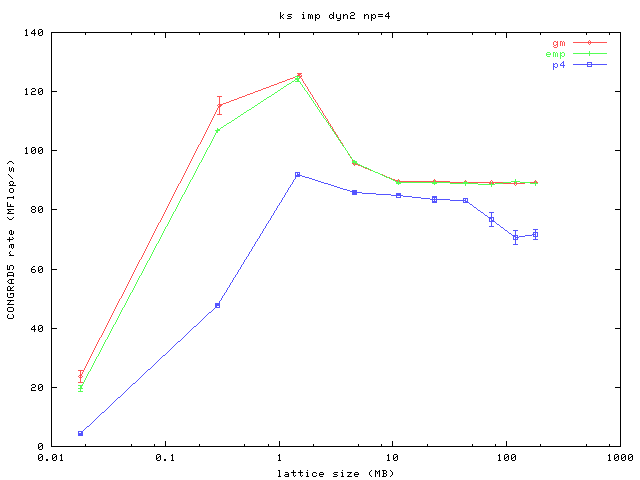
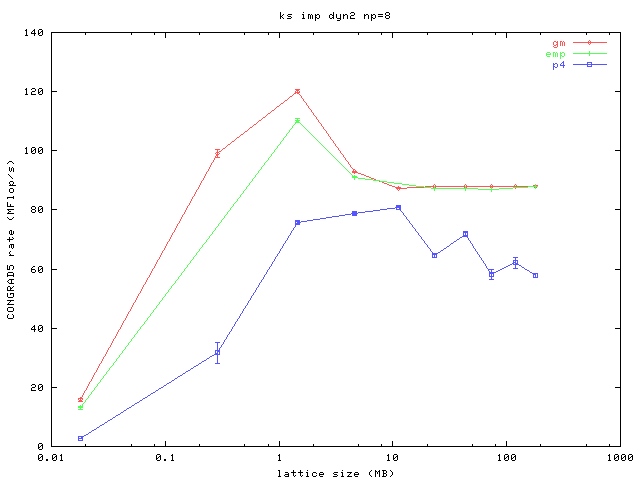
Here are four plots, one for each of four different processor count configurations, running on uniprocessor systems. The x-axis is the lattice size which represents the amount of computational work in each iteration, and also the amount of information passed to neighboring processors at the surfaces of the subvolumes. The y-axis measures the performance of the core routine in the code which does a conjugate gradient and includes the bulk of the message passing and the computation. More is better.
You can see that even at large lattice sizes where the code becomes computationally bound that the performance delivered by an MPICH using the P4 device over TCP on gigabit ethernet is not sufficient. The results for both MPICH/GM (using Myrinet 2000 with a 2 Gb/s link speed) and MPICH/EMP are similar and markedly better than P4.
A note on the absolute performance numbers. This data was generated on
733 MHz Itanium processors using the Intel compiler with flag "-O3". No
special inlining or assembly-language coding was enabled. Thus the raw
performance even for uniprocessor is lousy. But it does allow for
comparisons of the network at least.